In this post, we’ll take a look at the data provided in Kaggle’s Home Depot Product Search Relevance challenge to demonstrate some techniques that may be helpful in getting started with feature generation for text data. Dealing with text data is considerably different than numerical data, so there are a few basic approaches that are an excellent place to start. As always, before we start creating features we’ll need to clean and massage the data!
In the Home Depot challenge, we have a few files which provide attributes and descriptions of each of the products on their website. The idea is to figure out how relevant a particular search term(s) is to a product. As with most data science problems there are a LOT of different ways we could approach this. One exceptionally simple way would be to calculate the percentage of the search terms that are found in the product title and product description, normalized into the range. That would be a solid baseline/first submission for this task. We’re going to skip that, and move straight to an approach called TF-IDF. We’ll go into that in detail in the next post, but that approach attempts to determine the relevance of different words based on their frequency within each document (or product definition in our case) to the frequency within all documents.
The data for the Home Depot challenge is separated into several different files which we will want to combine into a single “document” for each product:
- attributes.csv – Contains each attribute/value pair for each product in the catalog
- product_descriptions.csv – Contains a single text description for each product in the catalog
- test/train.csv – Contains the product title and search terms used to build the model, along with the relevance for the training data (we won’t be dealing with this in this post, but there’s useful info in there as well)
Let’s start with the attributes file. There are multiple entries per product, one per attribute. The structure of this file is: product_uid, name, value. We could naively just concatenate all the values together into a single string to build the “document” for each product. However, if we take a close look at the attribute types, we can divide them into 3 main categories:
- general: general descriptions, typically the bullet points on the product info page
- flags: Some attributes only have yes/no values (‘MildewResistant’, ‘Waterproof’, ‘Caulkless’)
- measurements: Some attributes are explicitly measurements (‘Number of Pieces’, ‘Size of Opening’, ‘Product Width’)
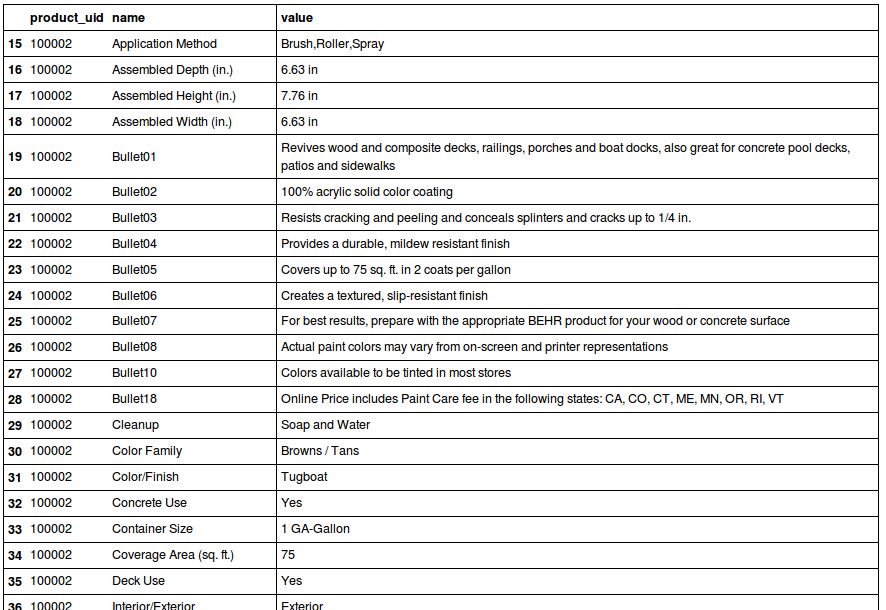
The values of flags won’t be very useful in a concatenated string. We’d just have a lot of “yes” and “no” values within each product without any information about what those represent. So instead, let’s replace that value with the feature name, and concatenate “Non” to the front if the original value is “no”:
binary_attrs = df[(df.value.str.lower() == 'yes') | (df.value.str.lower() == 'no')].name.unique()
idx = df.name.isin(binary_attrs) & (df.value.str.lower() == 'yes')
df.loc[idx, 'value'] = df[idx].name.map(lambda x: str(x).replace(' ', ''))
idx = df.name.isin(binary_attrs) & (df.value.str.lower() == 'no')
df.loc[idx, 'value'] = df[idx].name.map(lambda x: 'Non' + str(x).replace(' ', ''))
df[df.name.isin(binary_attrs)].head()

The measurement-type attributes are similarly unhelpful without some modification. For example, if the value is simply a number, that doesn’t really help to identify what measurement is being specified. For example, if the attribute name is “Number of Panels” simply including the value of “2” doesn’t really provide useful information for a feature unless we incorporate the attribute name into the value: “2” -> “2 Panels”
# Standardize the identifying phrase for measurement attributes
df.loc[df.name.str.lower().str.startswith('# of'), 'name'] = df.name.map(lambda x: str(x).replace('# of', 'Number of'))
# Find all the unique measurement attributes
count_attrs = df[df.name.str.lower().str.startswith('number of')].name.unique()
# Prepend the attribute name (without 'Number of') to the value
idx = df.name.isin(count_attrs)
df.loc[idx, 'value'] = df[idx].value + ' ' + df[idx].name.map(lambda x: str(x).replace('Number of', ''))
df[idx].head()

As you can see, this isn’t perfectly clean (cases like the above “Number of Faucet Handles” attribute pops up here and there) but this is definitely better than the alternative. Also in this example, this just provides extra weight in TF-IDF for ‘Handles’ which may be very useful as most products don’t have handles. For this data, the “Number of” attributes are one case of a measurement attribute, but there are many others (height, width, size, etc) that we’ll handle a bit differently, just with simple concatentation: “8” -> “A/C Coverage Area (sq. ft.) 8”
# We'll want to exclude the measurement attributes that start with "Number of"
numof = df.name.str.lower().str.startswith('number of')
# Build a list of all the other measurement attributes
measure_attrs = []
measure_attrs.extend(df[~numof & df.name.str.contains("depth", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("height", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("length", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("width", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("thickness", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("diameter", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("temperature", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("area (", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("area covered", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("size", case=False)].name.unique())
measure_attrs.extend(df[~numof & df.name.str.contains("opening (", case=False)].name.unique())
# Prepend the name to the value
idx = df.name.isin(measure_attrs)
df.loc[idx, 'value'] = df[idx].name + ' ' + df[idx].value
df[idx].head()

At this point we have a dataframe of modestly munged text data that can be turned into features. To be sure, this barely scratches the surface of what could be done for preprocessing, but it at least ensures that most of the data we have is available for the feature generator. A couple ideas of other things we could have done:
- In ‘Number of’ attributes, change value of “0” or “None” to “No” so it is closer to what a search term may be: “0 Bulbs Required -> “No Bulbs Required”
- Convert all measurement abbreviations to full words: “(sq. ft.)” -> “square feet”
- Dealing with apostrophes, ampersands, degree symbols, and other punctuation and other symbols
Rather than have multiple entries for each product (the ultimate level of detail we’ll eventually predict about) we must combine all the information we have into a single “document”. We’ll first do this for the attributes we’ve worked on, and then we’ll bring in the raw product descriptions and combine those as well
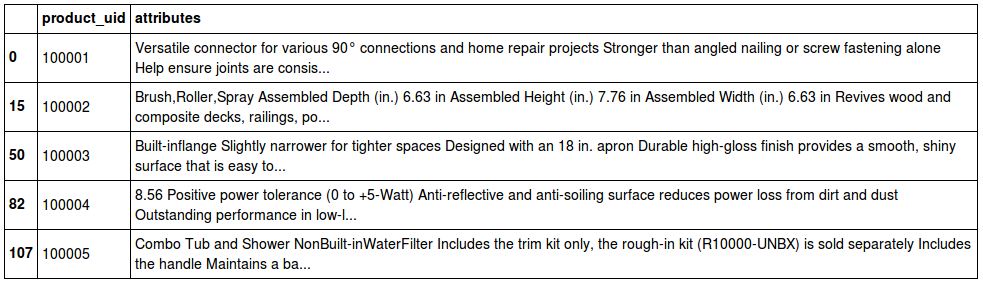
# Combine all the attributes from the same product into a single value
df['attributes'] = df.groupby('product_uid')['value'].transform(lambda x: ' '.join(map(str, x)))
df = df[['product_uid', 'attributes']].drop_duplicates()
df.head()
# We've got the attributes concatentated by product id, let's join them with the product descriptions too
descdf = pd.read_csv('product_descriptions.csv')
descdf.head()

# Make a single column that contains all words for each product df = df.merge(descdf, on='product_uid') df['document'] = df.attributes + ' ' + df.product_description del df['attributes'] del df['product_description'] df.head()
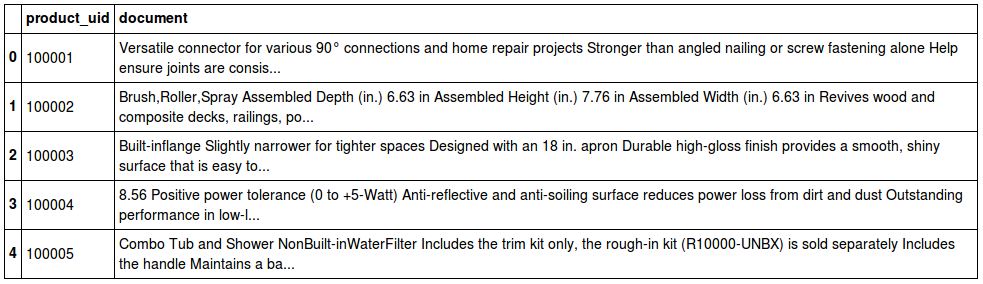
And now we’re ready for TF-IDF, in a post to follow
A Jupyter Notebook containing the full script can be found on Github: https://github.com/UltravioletAnalytics/text-features